Joint Probability Distribution
Joint Probability Distribution
결합분포(Joint Probability Distribution)는 두 개의 확률변수가 취할 수 있는 값들의 모든 쌍의 확률을 나타낸 것이다.
-
이산형 결합확률질량함수
-
연속형 결합확률밀도함수
Marginal PDF
주변확률밀도함수(Marginal PDF)는 다음과 같다.
두 확률변수 X, Y 가 다음을 만족할때 두 확률변수는 서로 독립이다.
- 이산형:
- 연속형:
- X와 Y가 서로 독립이면,
Covariance and Correlation Coefficient
-
공분산(Covariance)
-
상관계수(Correlation coefficient) - 선형의 연관성을 나타냄
확률변수 X, Y에 대해 다음과 같은 성질들이 있다.
-
-
-
-
-
-
이면
확률변수 X, Y가 독립일 경우,
-
-
-
- 주의: 인 것이 의 독립을 의미하지 않음
-
Conditional Probability Distribution
조건부 확률분포(Conditional Probability Distribution)는 두개의 확률변수가 있을 때, 하나의 확률변수의 값이 주어졌을때, 나머지 하나의 확률변수의 확률분포를 말한다.
-
이산 확률변수
두개의 이산 확률변수 X, Y에 대하여 X = x가 주어졌을때의 Y의 확률질량함수:는 로 고정 되어있을 때의 Y의 확률질량함수이다.
-
연속 확률변수
두개의 연속 확률변수 X, Y에 대하여 가 주어졌을 때의 Y의 확률밀도함수:는 가 고정되어 있을 때의 Y의 확률밀도함수이다.
- 하나가 이산 확률변수이고, 다른 하나가 연속 확률변수여도 잘 정의 될 수 있다.
Conditional Independence
두 확률변수 X, Y가 또 다른 확률변수 Z가 주어졌을때 서로 독립인 경우 X, Y는 조건부 독립(Conditional Independence)이라고 부른다.
즉, 모든 에 대하여, 또는 이다.
- 로 표시한다.
Random Vectors
각 원소 가 확률변수인 크기가 인 (열)벡터 를 확률벡터(random vector)라고 부른다.
-
확률벡터의 확률분포 - 결합확률분포(joint probability distribution)
-
결합확률질량함수(joint probability mass function):
-
결합확률밀도함수(joint probability density function):
-
결합누적확률분포(joint cumulative distribution function):
Mean of Random Vectors
Covariance Matrix
확률벡터 의 공분산 행렬 (covariance matrix) 는 다음과 같이 정의한다.
라고 하고, 라고 하자. 그러면, 공분산 행렬은 다음과 같이 표현된다.
- : Precision matrix
Marginal Probability Distribution
-
PMF:
-
PDF:
-
CDF:
Conditional PMF
이산인 확률변수 에 대하여 , 가 주어졌을때의 의 확률질량함수:
- 는 확률질량함수이다.
Conditional PDF
연속인 확률변수 에 대하여 가 주어졌을때의 의 확률밀도함수:
- 는 확률밀도함수이다.
- 이산 확률변수와 연속 확률변수가 섞여있어도 조건부 확률분포를 얘기할 수 있다.
Independence
확률변수 가 다음을 만족할 때 서로 독립이다:
모든 에 대해,
Discrete:
Continuous:
- 가 서로 독립이면,
Examples of Multivariate Probability Distribution
Multinomial Distribution
다항 분포 (Multinomial Distribution)는 독립시행에서 나오는 결과 (outcome)가 두 가지 이상일 때를 모형화 한 것이다.
k의 서로 다른 결과가 나오는 독립시행을 n번 시도 하였을때 각각의 결과가 나오는 횟수를 Xj라고 하자. 즉, 는 n번의 독립 시행에서 범주 j가 나온 횟수이다. 즉, 이다.
한번의 시행에서 j번째 범주가 나올 확률을 라고 하자. 즉, 이다.
이 때, 각 범주별로 나오는 횟수 는 다항분포 (multinomial distribution)을 따르고 다음과 같이 표시한다:
-
다항분포의 확률질량함수는 다음과 같다.
-
이항분포의 확장으로 볼 수 있다. 이면 다항분포는 이항분포와 같다.
-
Dirichlet Distribution
디리클레 분포(Dirichlet Distribution)는 연속 확률분포중의 하나로, 이면서 을 만족하는 확률변수들의 벡터 가 다음의 확률밀도함수를 가지는 경우이다.
은 확률밀도함수를 정하는 모수(parameter)이고,
-
로 나타낸다.
-
-
이면 디리클레분포는 베타분포와 같다.
Multivariate Gaussian Distribution
각 원소가 가우시안 분포 (정규분포)를 따르는 확률벡터의 분포를 다변량 가우시안분포(Multivariate Gaussian Distribution)라고 한다.
-
가우시안 확률벡터 (크기 )의 확률밀도함수는 다음과 같이 정의된다.
- 는 의 행렬식 (determinant)이다.
-
로 나타낸다.
-
각 원소가 표준정규분포이고 서로 독립이면, 로 표현된다. 는 단위행렬 (identity matrix)이다.
-
는 일반적으로 양의 정 부호 행렬 (positive definite matrix)이다.
-
양의 정부호 행렬은 Cholesky decomposition에 의해 로 표현되고 표준정규분포 벡터 를 이용하면 임을 알 수 있다.
-
이면, 즉 의 원소가 0 이면, 는 서로 독립이다.
- 따라서, 서로 독립인 가우시안 확률변수로 이루어진 다변량 가우시안 확률벡터의 공분산 행렬은 대각행렬이다. 즉, .
-
(적어도 하나의 가 0이 아닌 경우)는 가우시안분포(정규분포)를 따른다.
-
중에 개의 원소를 뽑아 만든 벡터 도 가우시안분포를 따른다.
-
의 원소는 이다.
-
인 경우, 이변량 가우시안 (bivariate Gaussian) 분포이며, 확률밀도함수는 다음과 같이 상관계수를 포함한 5개의 모수로 표현 할 수도 있다. 이때, 이다.
Partitioned Gaussian Distribution
가우시안 확률벡터의 일부로 만든 벡터의 분포를 분할 가우시안 분포 (Partitioned Gaussian Distribution)라고 하며, 평균벡터와 공분산 행렬은 원 확률벡터의 평균벡터와 공분산행렬을 분할하여 표현할 수 있다.
일 때, 로 나누어진다고 하자. 편의상 라고 하자. 실제로는 순서상관없이 두개의 그룹으로 묶어도 된다.
이때,
Conditional Partitioned Gaussian Distribution
로 주어졌을때 의 조건부 확률분포는
일때, 즉 이변량 가우시안 일때,
Mixure Distribution
여러개의 분포의 선형결합으로 이루어진 분포를 혼합분포(Mixure Distribution)라고 한다.
이산확률분포에서는 개의 이산확률분포의 선형결합으로 이루어진 다음과 같은 확률질량함수를 가진다.
이때 는 확률질량함수이고, 을 만족한다.
연속확률분포에서는 다음과 같은 확률밀도함수를 가진다.
Gaussian Mixure Distribution
들이 가우시안 확률밀도함수인 경우 가우시안 혼합분포(Gaussian Mixure Distribution)라고 한다.
를 표준정규분포의 확률밀도함수라고 하자. 즉,
인 경우, 의 확률밀도함수는 로 표현할 수 있다.
이 경우 개의 구성원을 가지는 가우시안 혼합 분포의 확률밀도함수는 다음과 같이 쓸 수 있다.
-
인 경우
-
, 즉, 가우시안 혼합 분포를 따르는 랜덤 추출된 데이터가 있다고 할때, 각 는 의 확률로 을 따른다고 해석할 수 있다.
-
군집분석의 모델로 사용할 수 있다.
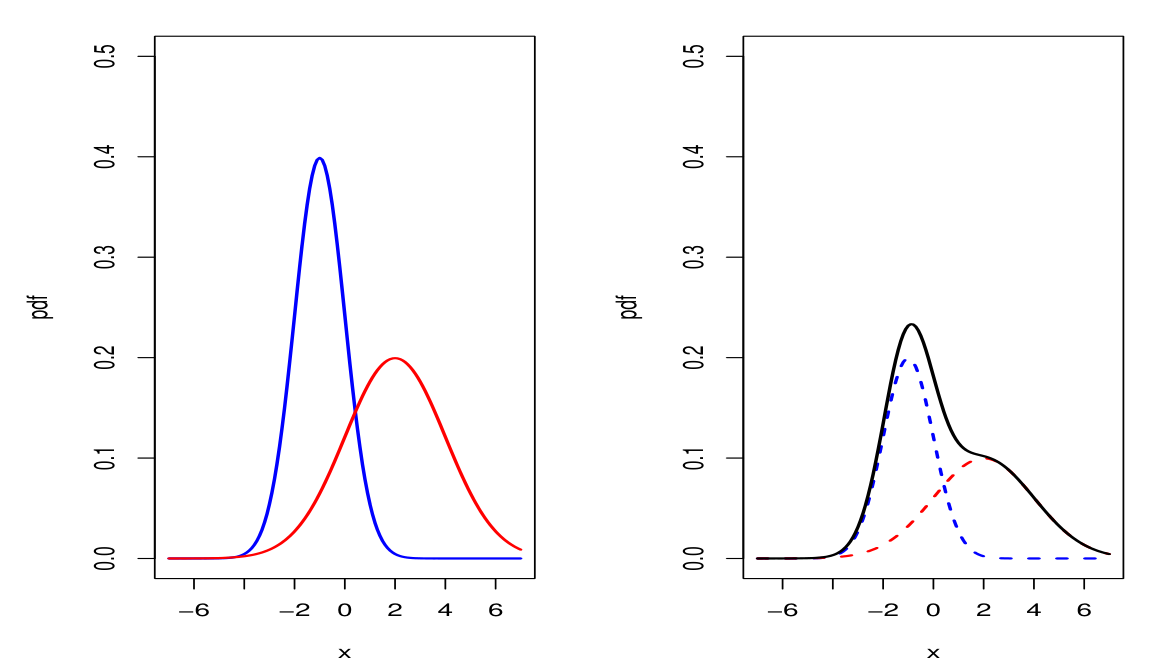
- 왼쪽: 파란선 , 빨간선
- 오른쪽: 파란점선 , 빨간점선 -> 까만선:
Sample Distribution
Distribution of Sample Mean
표본평균 (sample mean), 은 표본의 중심경향성을 나타내는 통계량이다.
-
모집단의 평균 (모평균)을 라고 하면, 표본평균은 의 추정량 (estimator)이다.
-
표본 가 모평균 , 모분산 인 모집단에서 추출된 랜덤표본일때,
-
무한모집단에서 추출된 랜덤표본일 경우,
-
크기가 인 유한모집단에서 추출된 랜덤표본일 경우,
Law of Large Numbers (LLN)
큰 수의 법칙(Law of Large Numbers, LLN)은 표본의 크기 n 이 커질수록 표본평균의 분산은 0에 가까워진다는 것을 말한다.
표본평균의 기대값은 모평균과 같고, 분산이 작아지므로, 는 모평균 의 근처에 밀집되어 분포함을 알 수 있다. 이러한 결과를 큰수의 법칙이라고 한다.
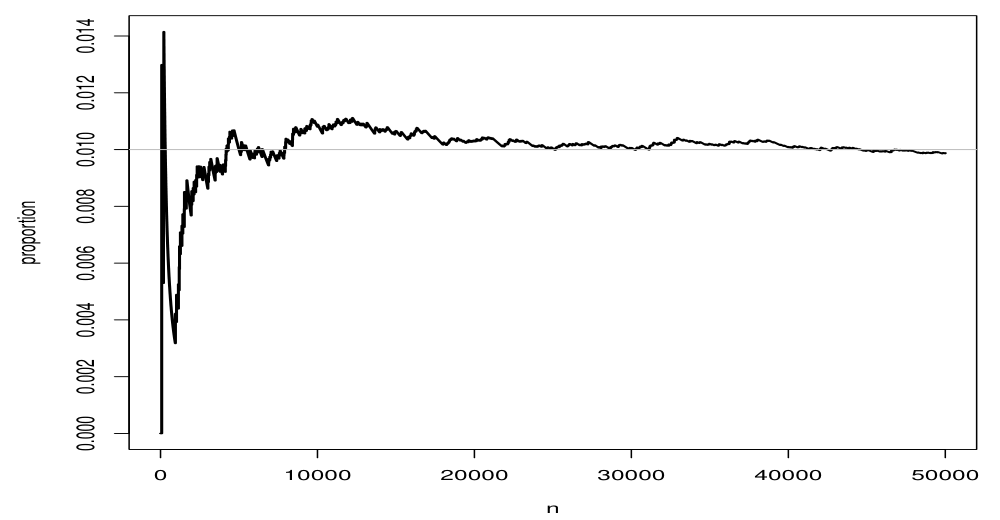
Central Limit Theorem (CLT)
중심극한정리(Central Limit Theorem, CLT)는 임의의 모집단에 대해 의 분포는 표준정규분포 에 근사한다는 것을 말한다.
유한모집단의 경우, 모집단의 크기 과 표본의 크기 이 충분히 크면(단 ) 의 값이 1에 근사하므로, 위의 성질이 성립한다.
중심극한정리를 통해, 모집단의 분포가 어떤 형태이든지 표본의 크기가 크면 표본평균의 분포를 정규분포로 근사할 수 있다.
- 즉, 의 분포 .
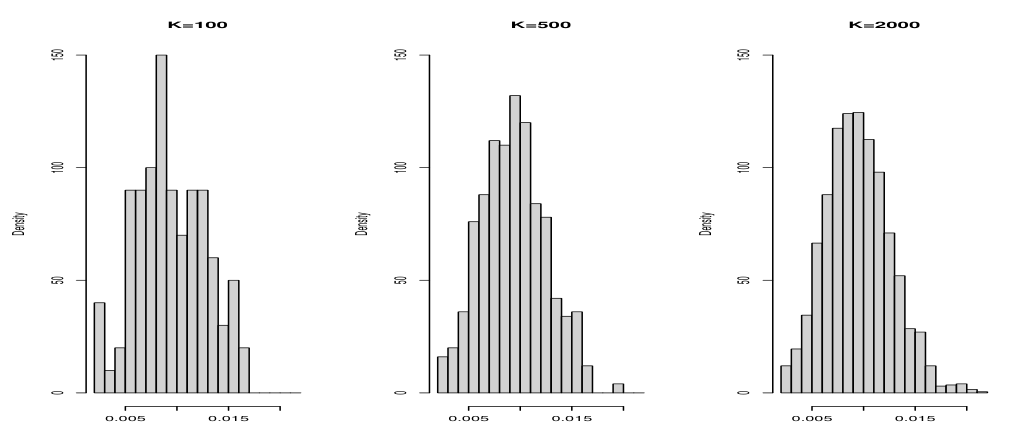
Normal Approximation Using the Binomial Distribution
이 성공률이 인 베르누이분포를 따르는 무한모집단의 랜덤표본이라고 하자. 이 경우, 은 이항분포 을 따른다.
중심극한정리를 적용하면, 이 충분히 클 때
의 분포는 표준정규분포 에 근사한다. (= 베르누이분포의 표본비율 .)
즉, 이 충분히 크고, 가 적당한 값이면, 를 이용하는 확률계산을 를 이용하여 근사할 수 있다.