Matrix Derivatives
Types of Matrix Derivative
| Type | Scalar | Vector | Matrix |
|---|---|---|---|
| Scalar | : | : | |
| Vector | : | : | |
| Matrix | : |
Dimension을 주의할 것!
Gradient and Hessian
- = the gradient of
- The transpose of the first derivatives of
- = the Hessian of
- The matrix of second partial derivatives of
- The Hessian is a symmetric matrix
Jacobian and Matrix Derivative
- Jacobian when
- Matrix derivative when
Useful Matrix Derivative
For ,
-
-
-
- if is symmetric.
Chain Rule
Chain Rule
Theorem: Chain Rule When the vector in turn depens on another vector , the chain rule for the univariate function can be extended as follows:
- If and where , then
(gradients from all possible paths)
- or in vector notation
Neural Net에서의 BackPropagation 기법의 기초가 된다.
Chain Rule on Level Curve
- level curve : 를 만족하는 의 집합.
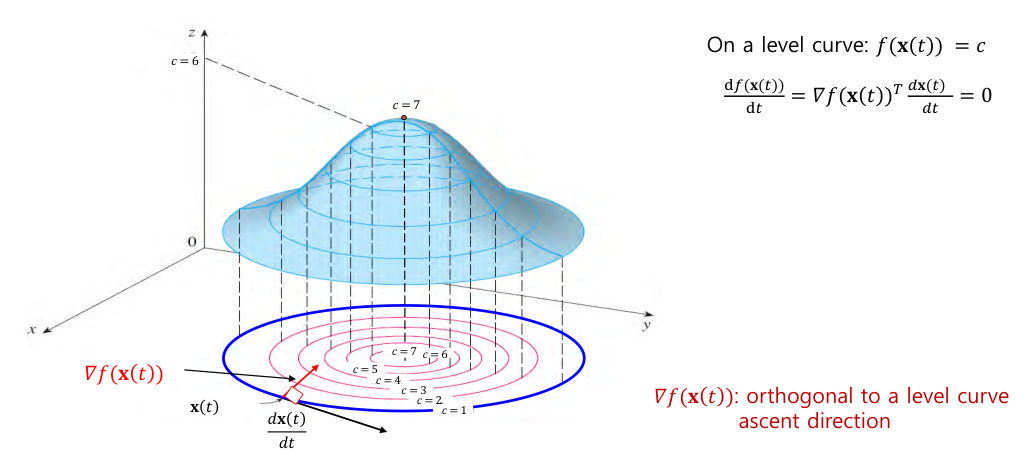
- On level curve ,
즉, 는 level curve에서 수직(orthogonal)이며, 가 증가하는 방향(ascent direction)을 가르킨다.
Directional Derivatives
- is continuously differentiable and , directional derivative of in the direction of is given by
Taylor Series Expansion
- First order
- Second order
추후 나올 일반적인 search(또는 learning) algorithm에서는 1st order expansion이면 충분하다.
Taylor Series Expansion을 통해 간단하게 가 ascent direction임을 보일 수 있다.