Scale-Invariant Feature Transform (SIFT)
Local Features for Correspondence Search
다음 문제를 생각해보자: ‘오른쪽 image에서 왼쪽 image에 해당하는 부분을 찾기’. 이 경우, 우리는 rotation, scale, color, lighting 등을 고려해야만 image를 찾을 수 있다.
![]()
HOG와 같은 방법은 특히 rotation에서는 꽤나 취약하다. 이 때 적용할 수 있는 다른 방법으로는, image에 대해서 회전 또는 확대 등이 적용되어도 쉽게 찾아낼 수 있는 특징적인 부분(local features)를 찾아내어 이를 연결하는 것이다. 이러한 방법을 scale-invariant feature transform (SIFT)이라고 한다.
SIFT는 현재에서도 Deep Learning을 적용하기 어려운 문제에 대해서 좋은 성능을 보여준다.
Identify the Interest Points
우선 두 image 상에서 local feature로 삼고자 하는 interest point를 찾아내는 작업이 필요하다. 이 때, 다음 기준으로 interest point를 선택하는 것이 좋다.
- image가 조금 달라지더라도 쉽게 해당 point를 다시 찾을 수 있다.

- 선택한 point에 대해서, matching되는 지점이 어디인지 쉽고 robust하게 찾을 수 있다.
일반적으로 position과 scale (size of patch)에 대해서 robust한 point를 찾는 것이 좋다.
Blob Detector
이에 대한 후보 중 하나로 blob이 있다. Blob이란 밝기나 색상이 일정한 image의 영역을 말한다. 이러한 blob을 찾아내는 blob detector에서 찾고자하는 blob의 크기를 바꿔가면서 찾아낸다면 다음과 같은 결과를 얻을 수 있다.
![]()
일반적으로 blob detector는 Laplacian of Gaussian (LoG) 또는 좀 더 효율적인 Difference of Gaussian (DoG)를 사용한다. Detecting 방법은 다음과 같이, 미리 정해진 scale의 LoG 또는 DoG filter를 image에 적용했을 때, peak가 발생한는 영역을 blob으로 볼 수 있다.
![]()
이 때, image에 대해서 여러 크기의 blob detector로 찾아낸 blob image들을 조합한 후, position과 scale 측면에서의 local maxima를 interest point로 선정하게 된다.
![]()
Scale-Invariant Feature Transform (SIFT)
앞서 구한 interest point들을 matching 시켜주기 위해서는, 우선 각 point에 대해서 point와 그 주변 image를 vector feature로 나타내는 descriptor를 구해야 한다. 특히 이는 geometric 및 photometric 차이에 대해서 invariance 해야만 같은 point에 대해서 같은 feature vector를 가질 것이다.
아래 그림을 본다면, 두 동일한 point에 대해서 단순하게 HOG를 계산하여 correlation을 구하면 당연하게도 좋지 않은 성능을 보여줄 것이다.
![]()
이를 위해서는 각 feature에 대한 normalization 작업이 필요하다.
- Scale normalization

- Orientation normalization (peak orientation이 0도가 되도록 회전)

위 작업 이후, correlation을 다시 계산한다면 훨씬 좋은 성능을 보여준다.
![]()
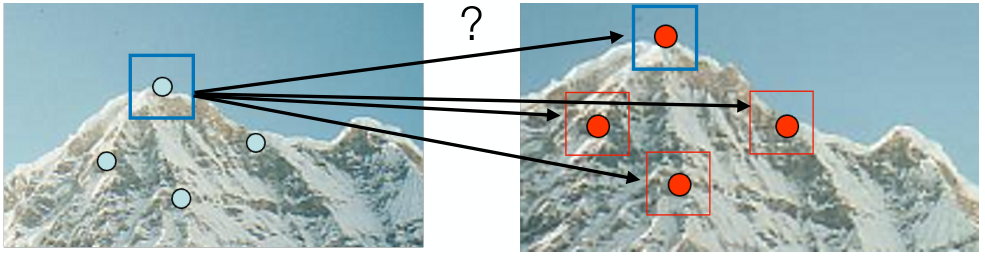
Match Local Features
Matching은 무척 직관적이다. 각 image에서 point 간 feature vector의 euclidean distance가 가장 짧은 두 point를 동일한 local feature로 선택한다.