Introduction to Reinforcement Learning
What is Reinforcement Learning?
Reinforcement learning (RL, 강화학습) 이란, agent가 환경과의 상호작용을 통해 목표를 달성하는 방법을 배우는 학습 방법을 말한다. 일반적으로 사람이 무언가를 배울 때, 여러번 시행착오를 통해 목표를 달성하게 되는데 이를 모방한 학습 방법으로 볼 수 있다.
RL은 구조와 학습 방법이 기타 machine learning 기법과 상이한 경우가 많기 때문에 machine learning을 분류할 때, supervised learning, unsupervised learning 그리고 reinforcement learning으로 나누는 경우도 있다.
Reinforcement Learning Problem
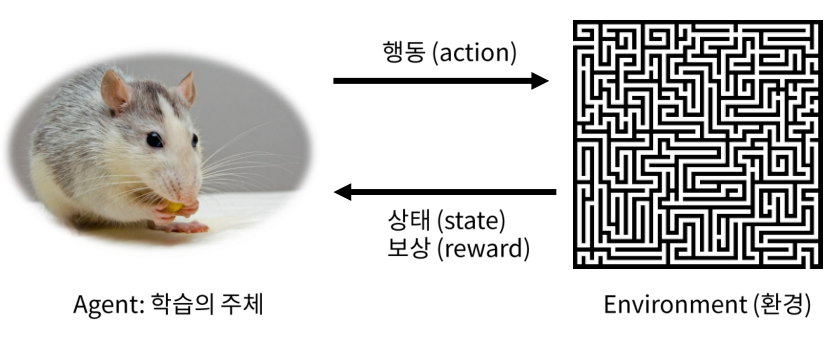
RL에서는 학습의 주체인 agent가 우리가 풀고자하는 문제를 갖고있는 environment (환경)과 상호작용을 함으로써 학습이 진행된다.
이 때 상호작용은, agent가 주어진 state (상태)에서 action (행동)을 수행하고 얻는 reward (보상)을 얻고 다음 state로 이동하는 것을 말하며, 최종적으로 얻는 reward의 합을 최대화하는 것이 일반적으로 학습의 목적이 된다.
Reward는 하나의 숫자로 표현되는 행동에 대한 평가지표이며, 지연되어 얻을 수도 있다 (예. 게임 승/패 등).
RL이 다루는 문제의 특징은 다음과 같다.
정답을 알지 못하지만, 행동에 대한 보상 및 다음 상태가 주어진다.
현재의 의사결정이 미래에 영향을 미친다.
문제의 구조를 모른다. 다만, 환경과의 상호작용으로 정보를 얻는다.
Basic RL Model
앞서 서술한 RL의 학습 과정을 formal 하게 표현하자.
Time step $t$ 에서, agent가 state $S_t$에 있을 때 action $A_t$를 수행하면, reward $R_{t+1}$을 얻고 새로운 state $S_{t+1}$로 이동한다.
Agent는 최종적으로는 reward의 누적합 $R_{1} + \gamma R_{2} + \gamma^2 R_{3} + \cdots$을 최대화 하는 것을 목적으로 한다. 이 때, $\gamma$는 discount factor라고 하여, 누적합에 대한 수렴 및 time-value를 반영해주는 값이다.
이 때, agent의 state, action, reward sequence를 episode, history 또는 trajectory라고 한다.
\[H_t = S_1,R_1,A_1,\dots,A_{t-1},S_t,R_t\]State는 지금까지의 history를 기반으로 결정된다. 즉, $S_t = f(H_t)$.
Major Components of an RL Agent
RL agent를 더 자세히 살펴보면 다음과 같은 요소들을 가지고 있다.
Policy
Policy (정책)이란 agent가 특정 state에서 선택하는 action을 결정하는 정책을 의미한다. 주로 $\pi$로 표시하며, randomness의 여부에 따라 deterministic policy와 stochastic policy로 나눈다.
- Deterministic policy: $\pi(s) = a$
- Stochastic policy: $\pi(a\mid s) = \mathbb{P}(a_t = a \mid s_t=s)$
Value Function
Value function (가치 함수)은 각각의 state 또는 action이 얼마나 좋은지 평가하는 함수를 말한다.
일반적으로 state $s$의 value는 해당 state에서 이후 얻을 수 있는 reward의 총합에 대한 기댓값으로 나타낸다.
\[V_{\pi}(s) = \mathbb{E}_{\pi} [R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots \mid S_t = s]\]위 식에서도 볼 수 있듯이, value function은 policy $\pi$에 의해서 달라진다. 이는 같은 state에서 어떤 action을 취하느냐에 따라 얻을 수 있는 reward의 기댓값은 달라지기 때문이다.
State-action pair에 대한 가치함수로 Q-value가 있다. 이는 추후 자세하게 서술한다.
Model
RL에서 model 은 가끔 특별한 의미로 사용되는데, agent가 추측하는 environment를 나타낸다.
일반적으로, 어떤 state $s$에서 action $a$를 했을 때, 다음 state가 $s’$이 될 확률을 나타내는 transition probability $P_{ss’}^a$와 그 때 얻을 reward $R_s^a$로 표현될 수 있다.
\[P_{ss'}^a = \mathbb{P}[S_{t+1} = s' \mid S_t = s, A_t = a]\] \[R_s^a = \mathbb{P}[R_{t+1} \mid S_t = s, A_t = a]\]이러한 요소들은 일반적으로 전혀 또는 대부분 알려져있지 않기 때문에, model을 모르는 상태의 RL이 일반적이라고 볼 수 있다.
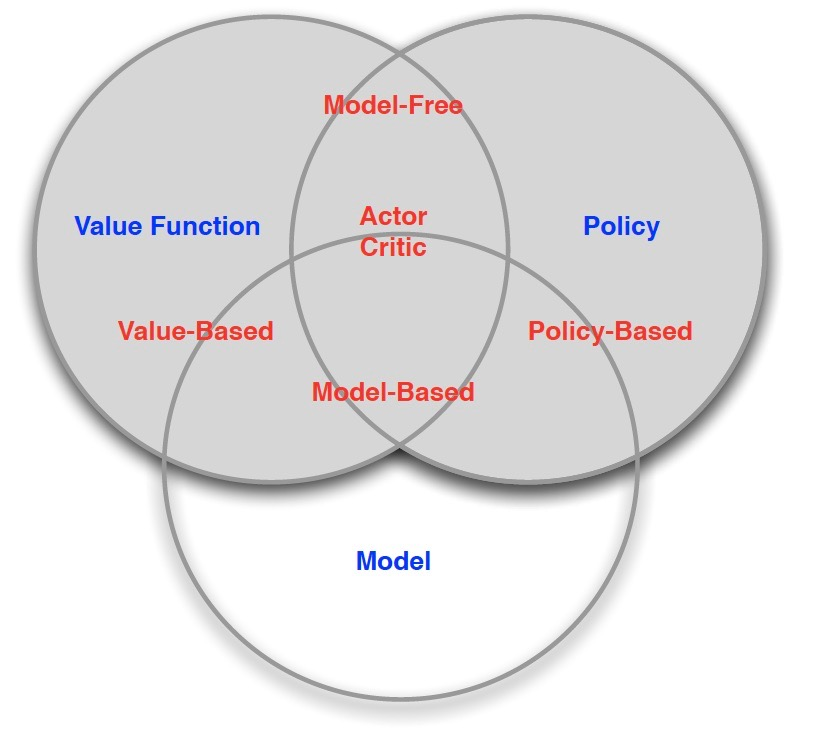
Types of Reinforcement Learning
위 3가지 요소를 기반으로 RL을 나눠보면 다음과 같이 구분될 수 있다.
Model-based RL
Model-free RL (일반적인 RL)
Value-based RL
Policy-based RL
Actor-critic