Hyperparameters in Deep Learning
Hyperparameter에 관한 기초 내용은 아래 post를 참조하길 바란다.
Hyperparameter를 더 세부적으로 분류하면 모델의 구조에 관여하는 architectural hyperparameters와 모델의 학습 과정에 관여하는 training hyperparameters가 있다.
Training Hyperparameters
아래와 같이, 모델의 training process에 관여하는 hyperparameter들을 training hyperparameters라고 한다.
Learning rate: 모델을 학습할 때 weight를 업데이트하는 속도를 결정
Batch size: 한 번의 학습에서 사용할 데이터 sample의 수를 결정
Number of epochs: 전체 dataset을 몇 번 반복해서 학습할지를 결정
Optimization algorithm and momentum: SGD, Adam, RMSprop 등 어떤 최적화 알고리즘을 어떻게 사용할지를 선택
Weight initialization: weight를 초기화하는 방법을 결정
Learning Rate
Deep learning에서 모델의 effective capacity는 모델이 학습할 수 있는 패턴의 복잡성과 이를 일반화할 수 있는 능력을 의미한다. 즉, capacity가 큰 모델은 training data의 복잡성을 잘 학습할 수 있지만 그에 따른 overfitting 발생 가능성도 올라간다. 반면 capacity가 작은 모델은 underfitting 발생 가능성이 커진다.
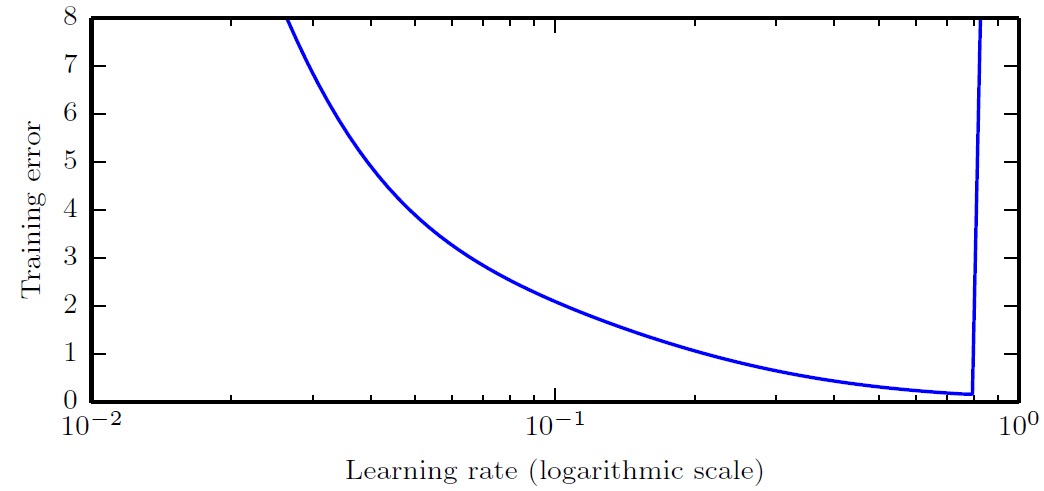
Learning rate는 모델의 effective capacity를 가장 크게 조절하는 hyperparameter로 가장 중요한 training hyperparameter로 볼 수 있다. 만약 learning rate가 매우 크다면, gradient descent 과정이 제대로 수행되지 않아 오히려 training error가 크게 증가할 수 있다. 반면에 learning rate가 너무 작으면, local minimum을 벗어나지 못해 학습이 제대로 이루어지지 않을 가능성이 크다.
Architectural Hyperparameters
아래와 같이, model architecture를 결정하는 hyperparameter들을 architectural hyperparameter라고 한다.
Number of layers: 모델이 몇 개의 층으로 구성될지 결정
Type of layers: CNN, RNN, LSTM 등 어떤 유형의 layer를 사용할지 결정
Number of units per layer: 각 층에 몇 개의 neuron을 사용할지 결정
Activation function: ReLU, Sigmoid, Tanh 등 어떤 activation function을 사용할지 결정
Filter size: CNN에서 각 필터의 크기를 결정
Stride: CNN에서 필터 이동의 간격을 결정
Pooling size and type: Max Pooling 또는 Average Pooling의 크기와 유형을 결정
Dropout rate: dropout layer에서 node 비활성화 비율을 결정
Padding: CNN에서 input에 어떤 padding을 적용할지 결정
Network architecture: ResNet, VGG, Inception 등 특정 네트워크 구조를 선택
Architectural hyperparameter의 optimization은 높은 cost로 인해 일반적인 grid 또는 random search 방법을 적용하기가 사실상 불가능하다.
따라서, 일반적으로는 previous research에서 제안한 model 구조를 따르는 것을 추천하나, 만약 새로 model을 생성해야 하는 상황이라면 처음엔 simple한 모델이 되도록 설정하고, 이후 모델이 가지는 complexity가 점점 커지도록 바꿔보는 방식을 추천한다. 다만 이때에도 문제와 dataset에 따라 모델의 complexity를 증가시키는 방법이 달라지므로 풀고자하는 문제와 관련된 선행 연구들의 trend를 체크하는 것이 중요하다.