Histogram of Oriented Gradients (HOG)
Histogram of Oriented Gradients (HOG)
Pixel Intensity Correlation
Object detection 문제를 고려해보자.
가장 쉽게 생각할 수 있는 방법 중 하나는, 우리가 찾고자하는 object를 image 상에서 sliding 시키면서 가장 image와 가장 높은 correlation을 갖는 부분을 찾는 것이다.
하지만 이 방법은 같은 모양, 같은 크기, 같은 방향, 같은 시점인 경우에만 잘 찾을 수 있다는 매우 큰 단점이 있다.
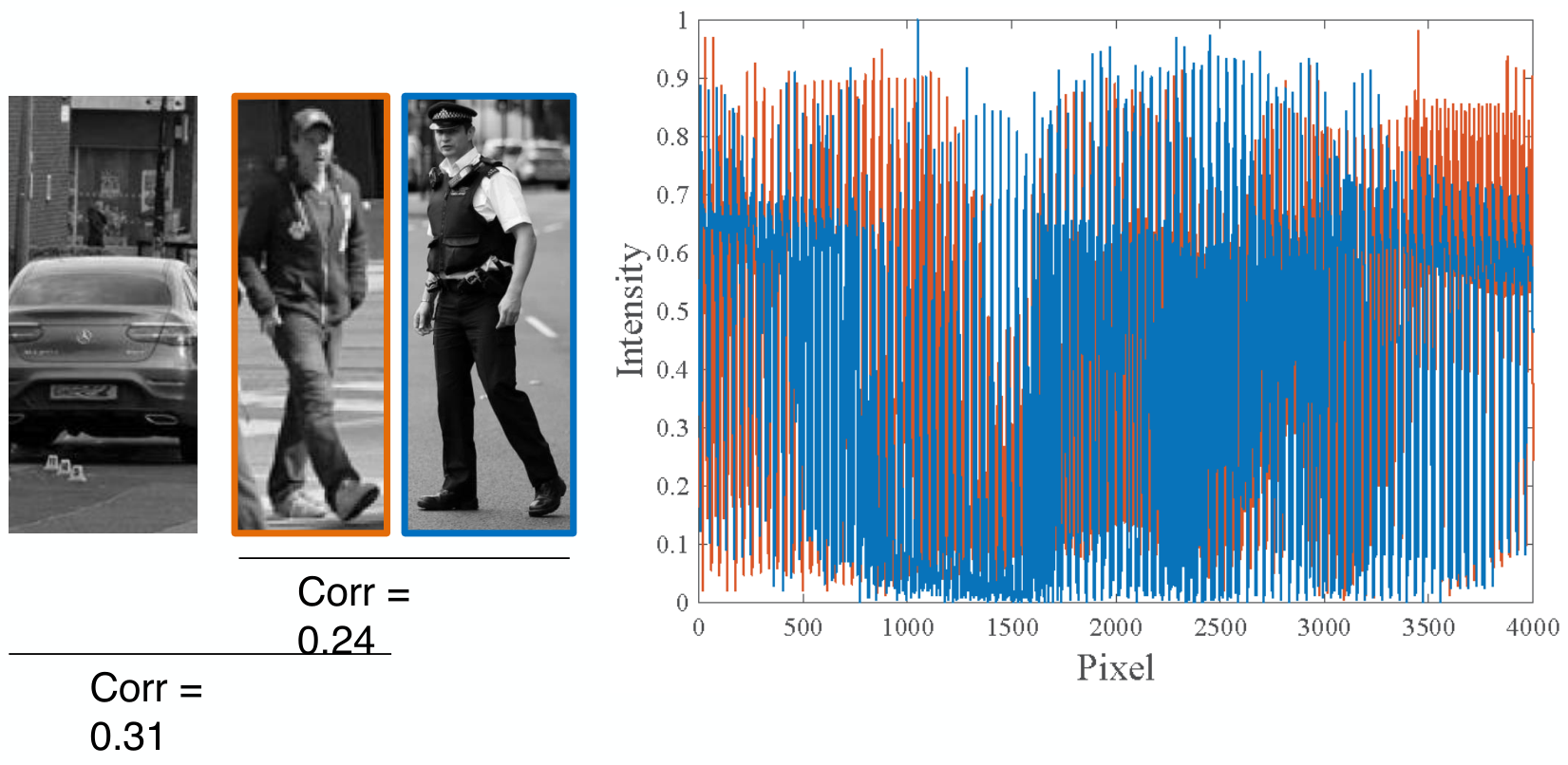
만약, 어느정도 유사한 사진 두 장이라고 하더라도, 단순한 pixel intensity 간의 correlation으로 object detection을 수행하는 것은 좋지 않은 성능을 보여준다.
아래 그림을 보면, 서로 다른 두 사람의 intensity correlation보다 전혀 상관없는 차와 사람의 correlation이 더 높은 것을 볼 수 있다.
Gradient Distribution
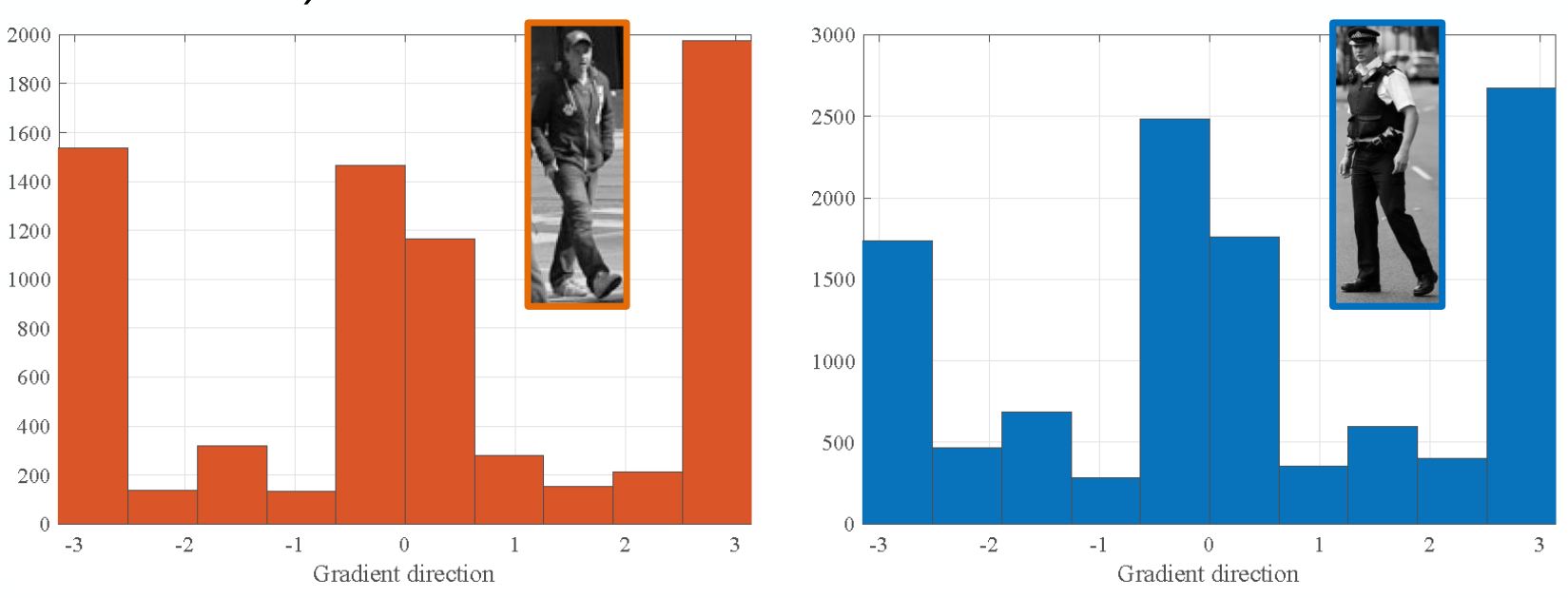
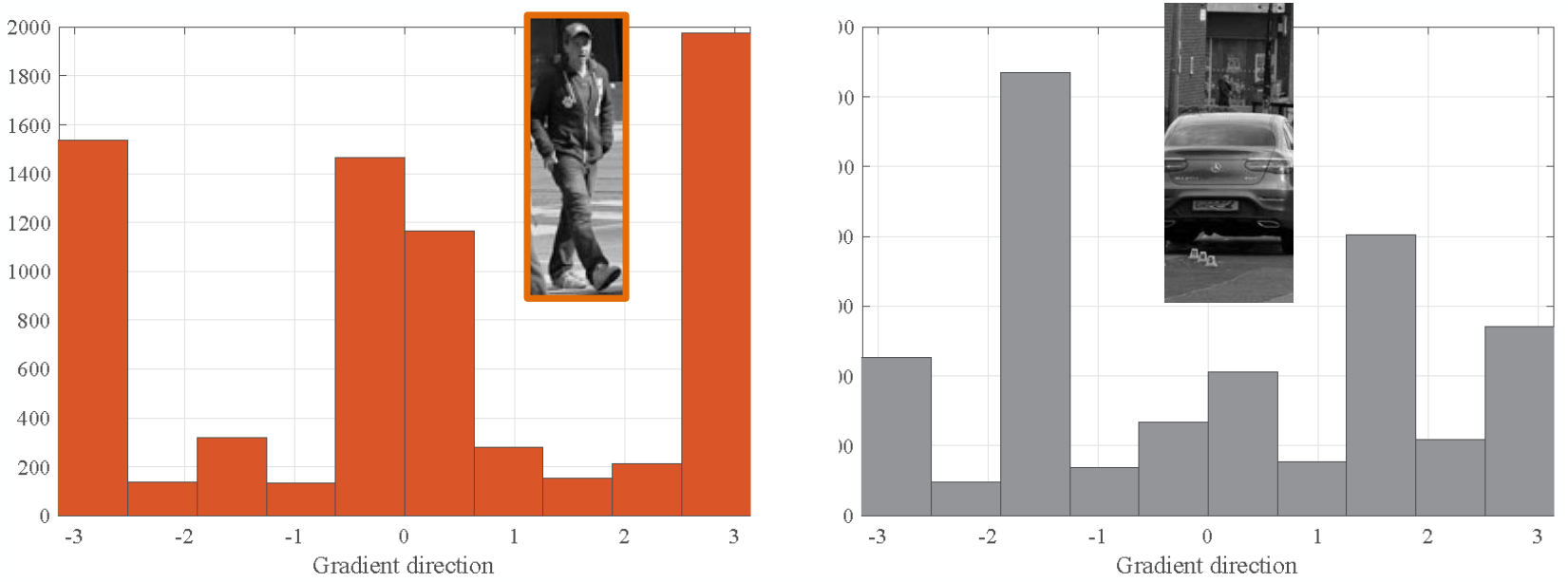
이러한 문제를 해결하기 위해, image의 edge의 형태를 통해 image의 correlation을 계산하는 방법이 나타났다. 이는 image의 gradient를 모두 계산(세부 내용 참고)한 후, gradient의 angle을 기준으로 histogram을 만드는 것이다.
Image rotation과 lighting에 좀 더 robust한 계산을 위해 histogram을 사용한다.
앞선 예시에서 gradient distribution으로 비교 시, 사람 간의 correlation이 차와 사람의 correlation보다 훨씬 큰 것을 한 눈에 알 수 있다.
Histogram of Oriented Gradients (HOG)
위 Gradient distribution은 image 전체의 gradient(global gradient)를 histogram으로 나타낸 것으로, 단순히 histogram만 보면 feature의 spatial relationship이 보존되지 않을 수 있다.
아래 두 그림은 동일한 histogram을 갖고 있지만, 같은 object로 볼 수는 없다.
따라서, 이를 보완하기 위해, image를 작은 block들로 쪼개고, 각 block에 대한 gradient(local gradient)를 histogram으로 각각 나타낸다.
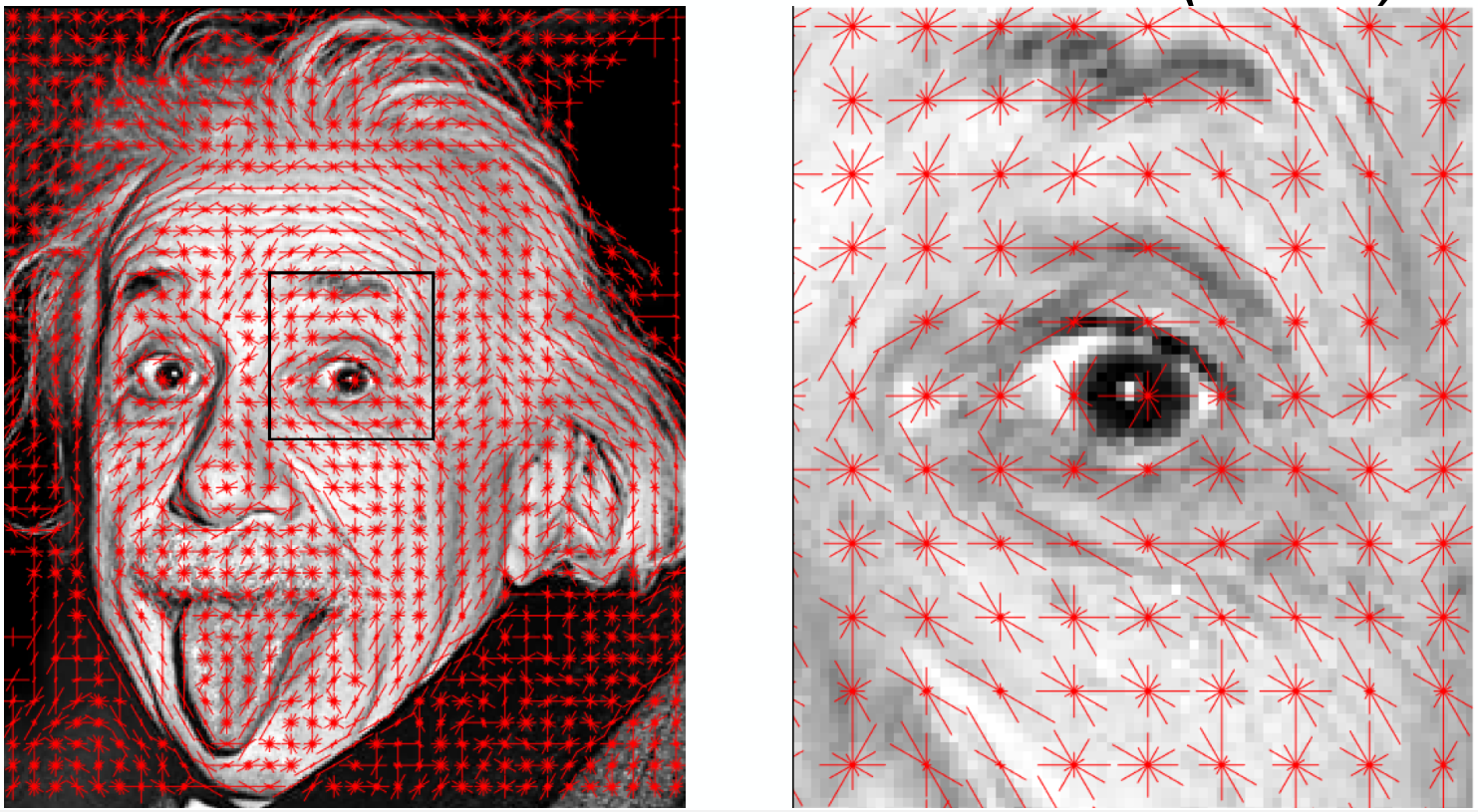
이러한 기법을 histogram of oriented gradients, 또는 HOG라고 말한다.
Details of HOG
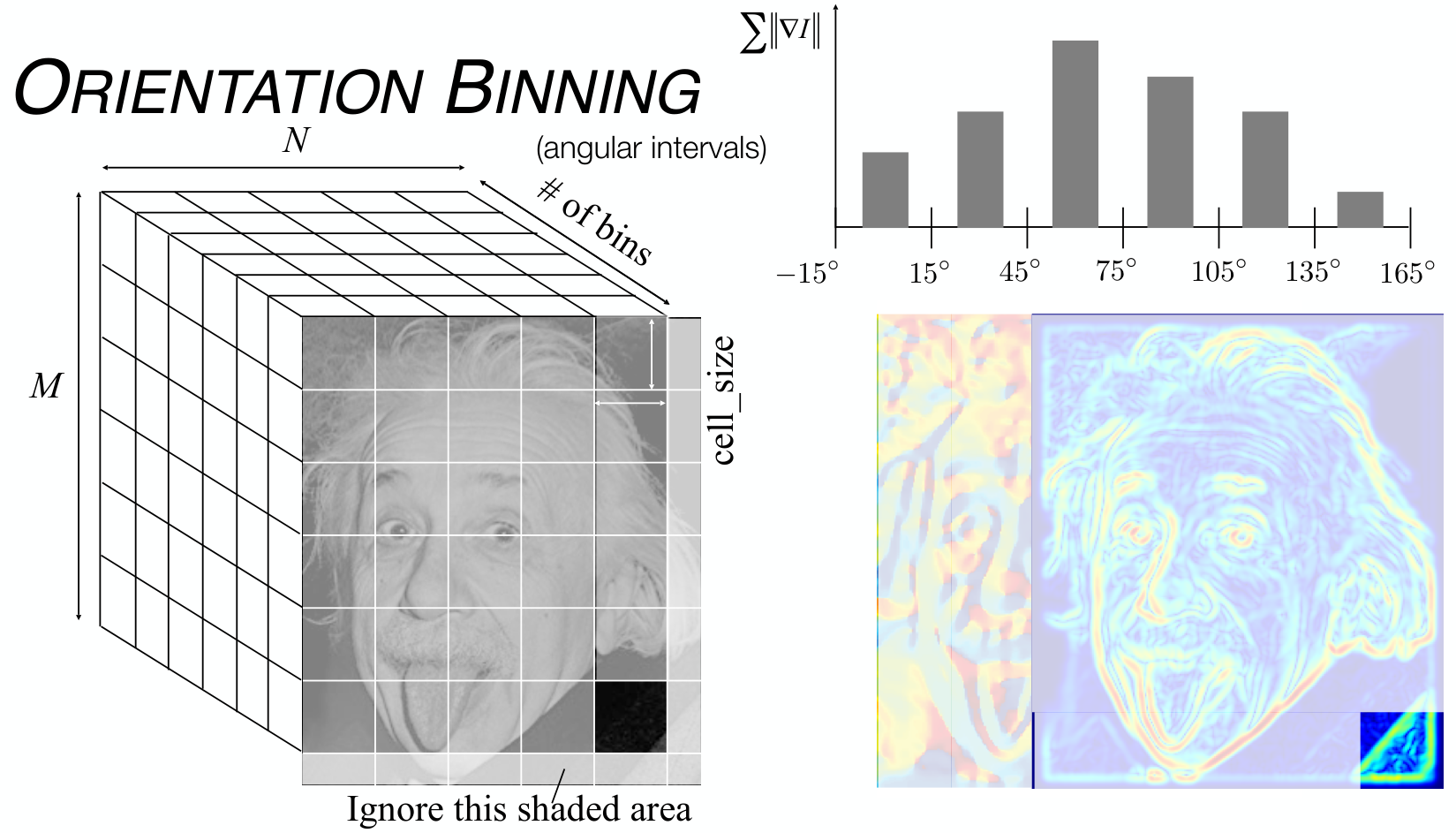
Orientation Binning
기본적으로 하나의 block에는 histogram의 bin 개수 만큼의 data가 생성된다. 따라서 HOG를 적용한 Image는 ‘# of blocks’ x ‘# of bins’만큼의 data가 생성된다.
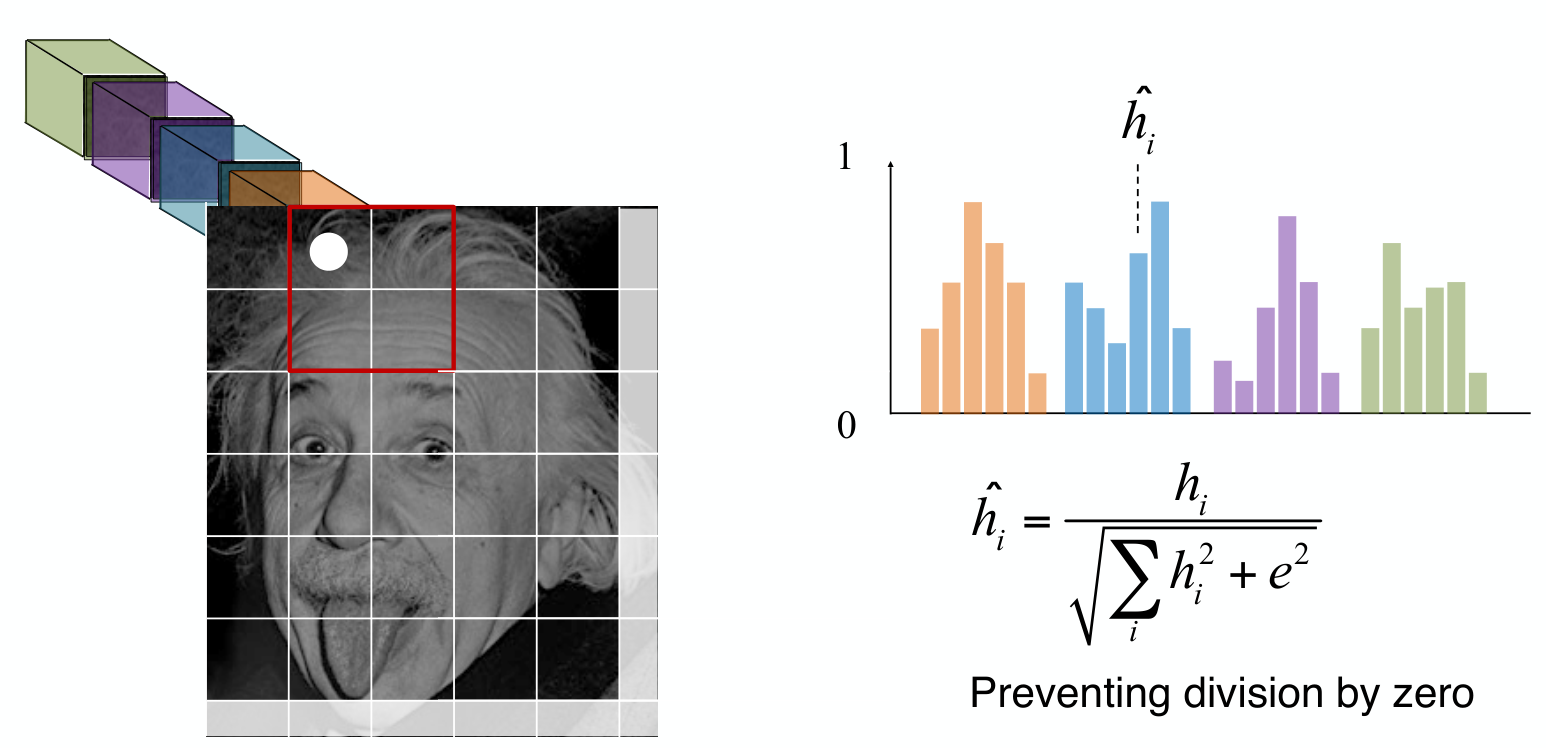
Block Normalization
Gradient histogram의 크기는 각 angle bin에 해당하는 pixel의 intensity 크기의 합이다. 따라서, 동일한 shape을 가지고 있다고 하더라도, image 상의 contrast가 높은 image에서 histogram의 크기가 더 커지게 된다.
이러한 현상을 해결하고자 각 block에 대해서 block normalizing 과정을 적용한다.
- Neighboring block들을 구한다.
- Neighboring block들을 이용해서 normalize를 진행한다.
- Normalized block들을 연결한다.
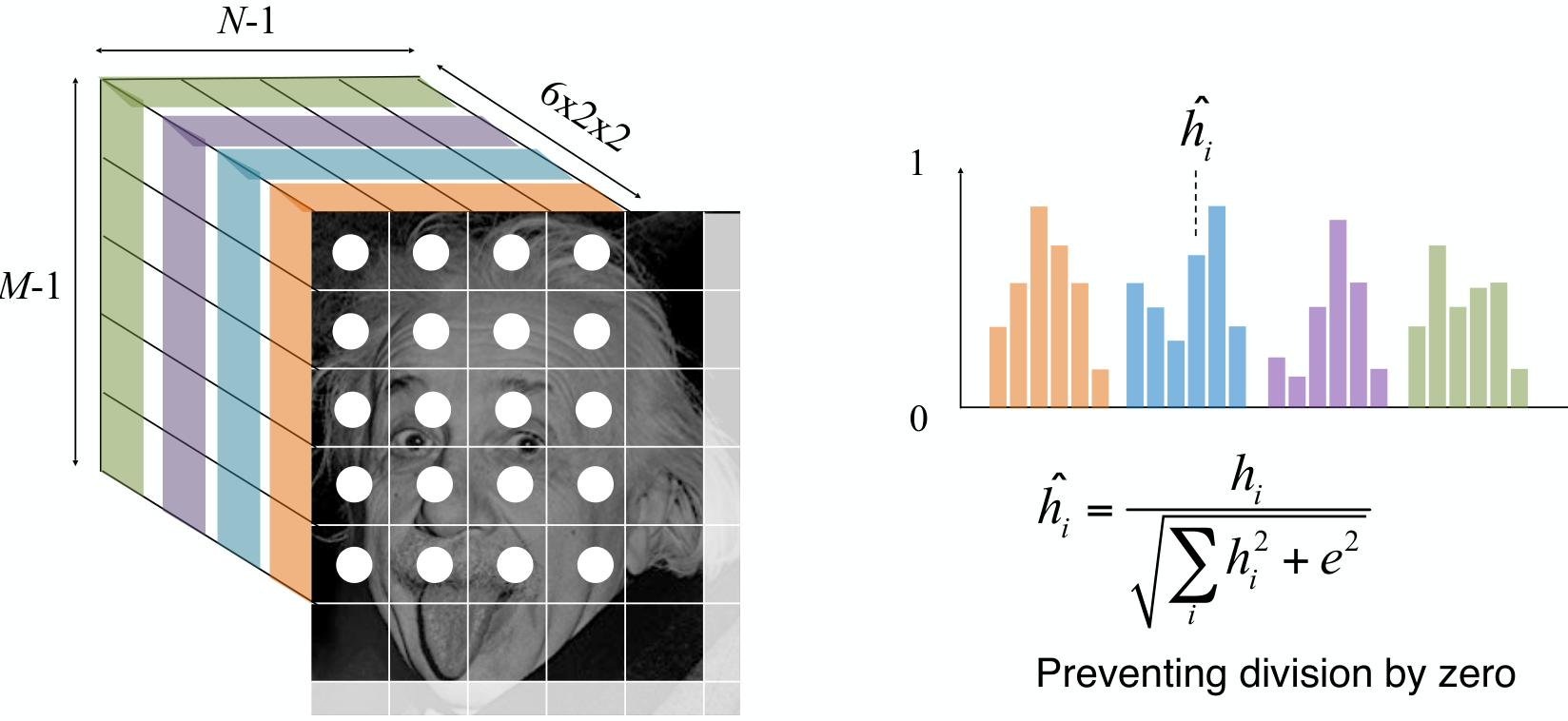
최종적으로 연결된 normalized block들은 vector화 할 수 있으며, 이를 feature로 사용한다.
Applications of HOG
Face Detection
주어진 얼굴 이미지에 대해서 target image 상의 image window들과 HOG feature vector의 cosine similarity를 사용해서 face detection이 가능하다.
우선 특정 threshold를 초과하는 image window들을 bounding box(BB)로 표시하면 다음과 같이 나올 것이다.

당연하게도 pixel이 한칸 바뀐다고 해서 correlation이 크게 변하지 않기에 비슷한 영역에 수많은 BB가 생성된다.
이들 중 가장 좋은 BB를 찾기 위해서 유사한 위치의 BB set들에 대해서 가장 높은 correlation score를 갖는 BB를 제외하고는 다 제거하는 non-maximum suppression 방법을 적용한다.
만약 찾으려는 object의 image와 실제 image 상의 object의 크기가 다른 경우는 image의 resolution을 여러 수준으로 바꿔가면서 반복적으로 알고리즘을 적용하여 가장 높은 correlation score을 보여주는 image를 찾는다.
Object Recognition with HOG
HOG feature vector를 활용해서 SVM classifier를 통한 object recognition도 가능하다.

Deep Learning 등장 전까지는 좋은 성능을 보여주는 방법 중 하나였다.
Deformable Part Model (DPM)
전통적인 HOG의 경우 어느정도 형태가 고정적인 object에 대해서는 효과적이었으나, 사람과 같이 다양한 형태 또는 Pose를 갖는 object에 대해서는 성능이 떨어졌다. 특히, 손이나 다리와 같은 object는 굉장히 찾기가 어려웠다.
Deformable part model (DPM)은 이러한 이슈를 해결하기 위해 제안된 framework이다. DPM은 물체의 전체적인 모양을 나타내는 root template과 물체의 세부 부분을 나타내는 작은 템플릿들인 part templates를 미리 정하고, 각 part template의 위치가 root template에 대해서 어떻게 변형될 수 있는지를 수학적으로 모델링하여, 부분들이 약간 이동하거나 회전해도 문제없이 찾을 수 있도록 설계되었다.
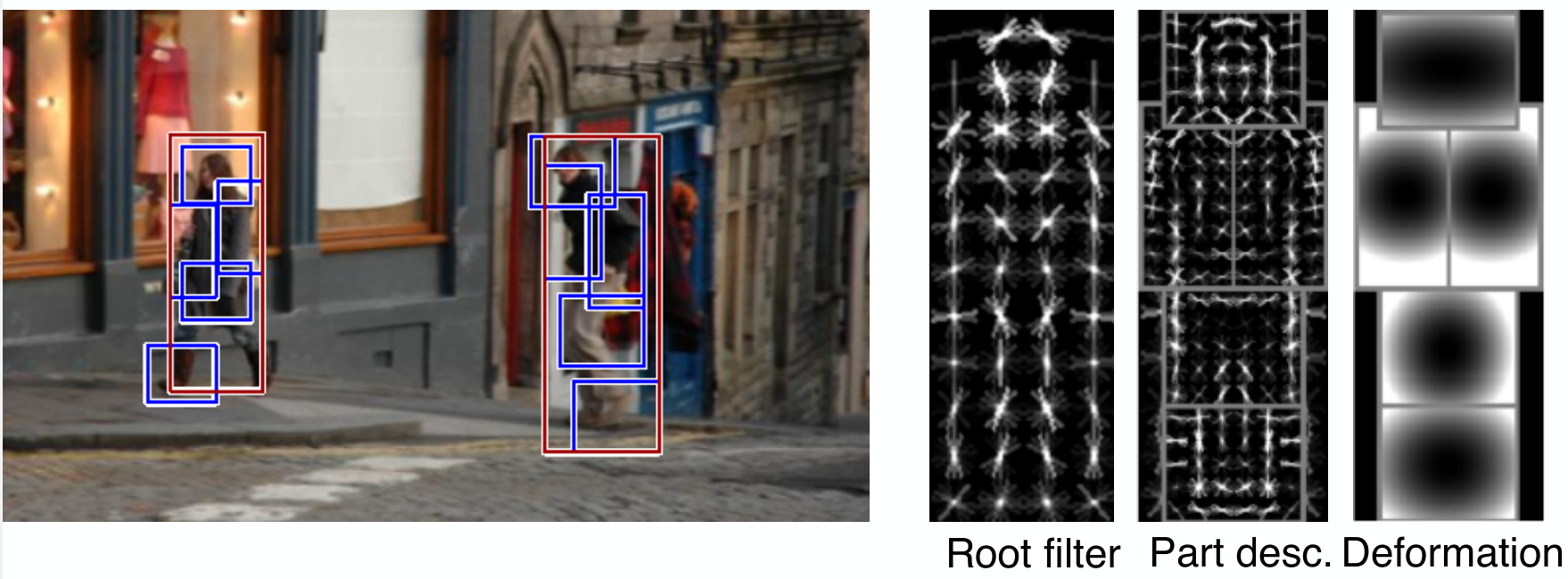
이 역시, Deep Learning 등장 전까지는 좋은 성능을 보여주는 방법 중 하나였다.