Convolutional Neural Network
Image 분류 및 처리 등에 있어서 탁월한 성능을 보인 convolutional neural network (CNN)에 대해서 정리하고자 한다. CNN은 FNN에서 feedforward 과정에서 진행했던 matrix multiplication 연산을 convolution 연산으로 바꾼 것이 가장 큰 핵심으로, 기존의 모델이 image의 spatial structure를 잘 고려하지 못했던 점을 개선하였다.
2D image에서의 convolution이 무엇인지, 어떤 성질을 갖는지는 이전 post를 참조하길 바란다: 2D convolution
CNN은 기존의 FNN과는 크게 다른 두 가지의 component를 갖는다: convolution layers과 pooling layers (참고: FNN).
Convolution Layer
32x32x3 차원을 갖는 image를 생각하자. 일반적으로 이러한 경우 image의 가로와 세로 길이가 32이고, channel이 3개(e.g. R, G, B)인 것을 의미한다.
Convolution Layer는 filter 또는 kernel을 갖고 있는데, 해당 kernel은 input data와 convolution 연산을 통해 image의 (hidden) feature를 뽑아내는 역할을 갖는다.
Convolution layer에서 학습되는 것은 filter이다.
만약 filter가 5x5 size를 갖는다고 하면, convolution 연산을 통해 activation map을 생성한다. 이 때, input의 channel 수 만큼 자동으로 dimension을 확장한다.
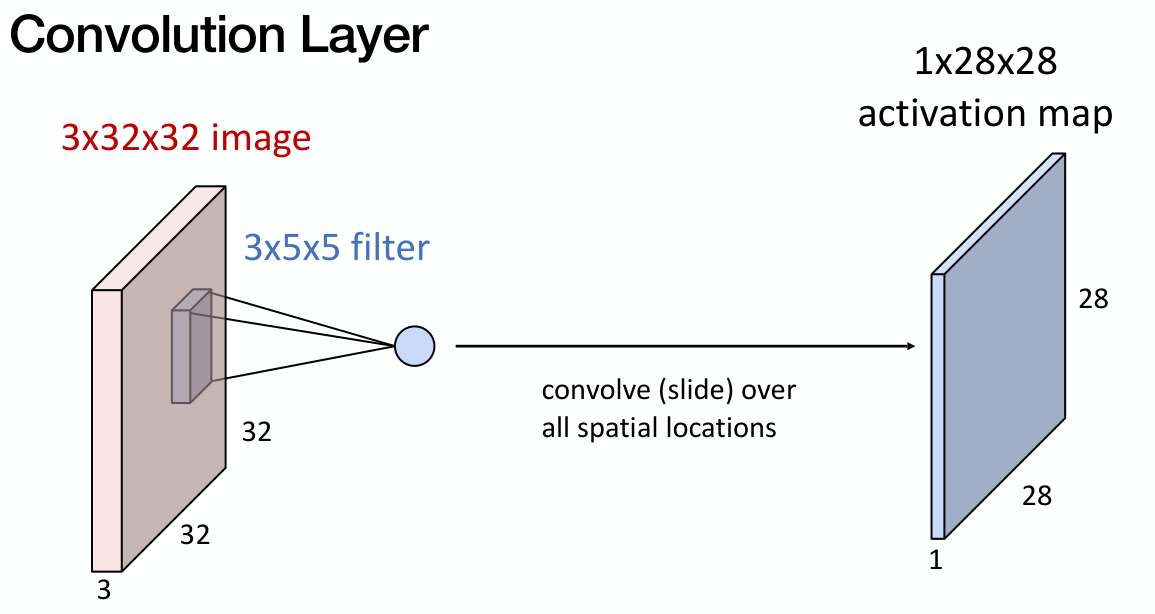
Convolution layer는 여러 개의 filter를 가질 수도 있다. 하나의 filter가 하나의 activation map을 만들기 때문에, 최종적으로 convolution layer의 output의 차원은 ‘filter 수’x28x28 이 된다.
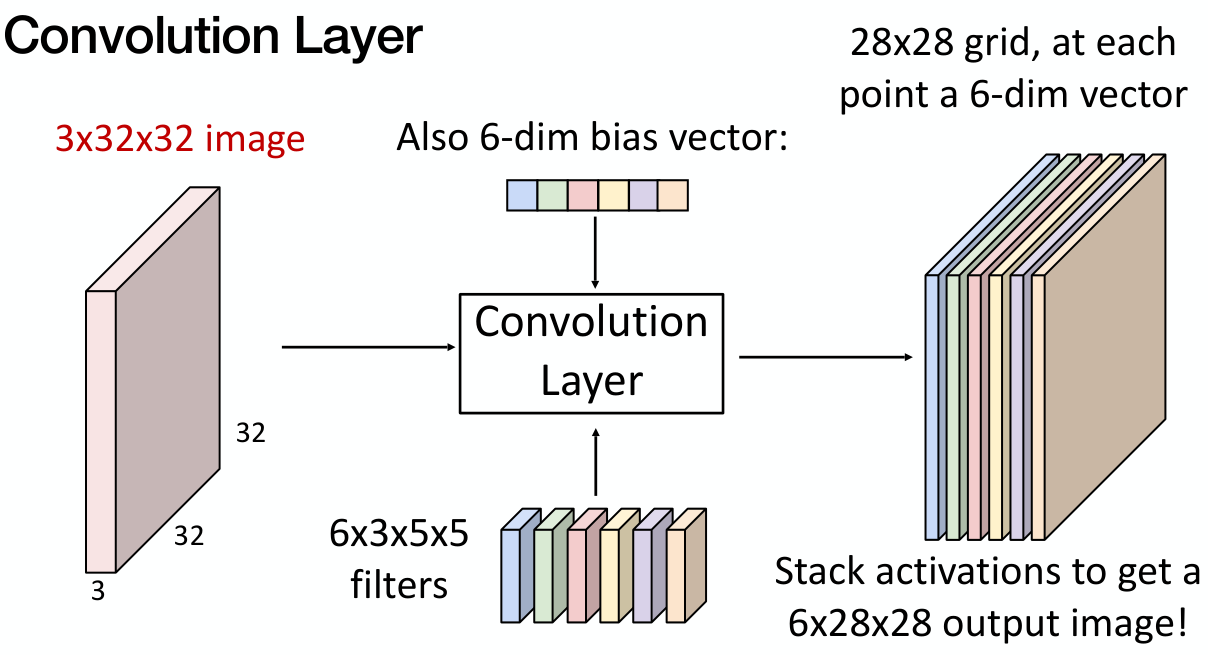
일반적으로 학습은 batching을 적용하기 때문에, 이를 고려하면 최종적으로 하나의 convolution layer는 다음과 같다.
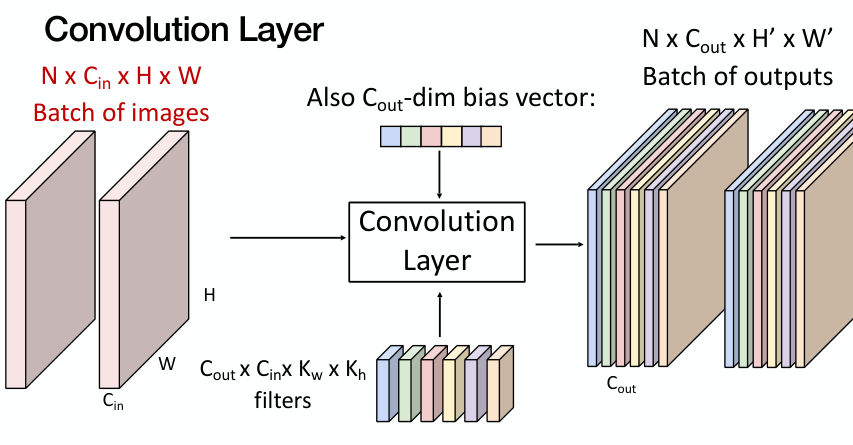
- $N$: batch size
- $C_{in}$: input channel 수
- $C_{out}$: output channel 수 (= kernel 수)
- $K_w, K_h$: kernel 크기
- $H, W, H’, W’$: input과 output의 크기
실제적으로 CNN 모델을 구현하는 과정에서는 각 layer를 거치면서 output의 dimension이 어떻게 변하는 지를 사용자가 직접 계산 할 수 있어야 한다.
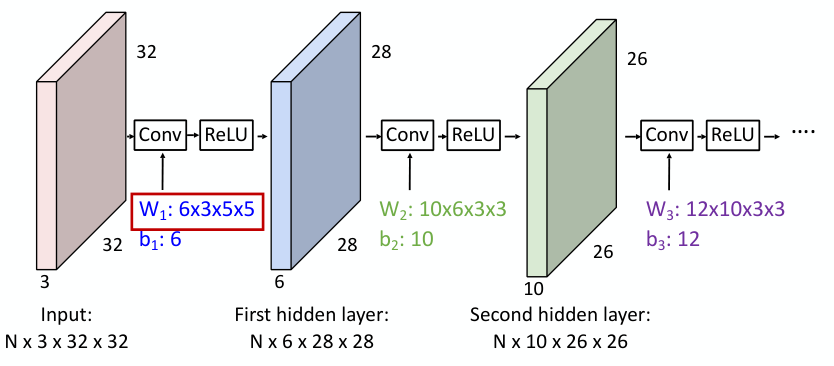
이러한 convolution layer를 겹겹이 쌓을 수도 있다.
Ideas in Convolution
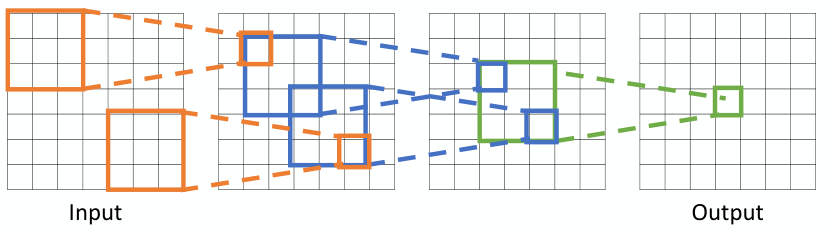
Local Connectivity and Hierarchical Feature Extraction
일반적인 FNN 모델의 경우, 모든 output unit은 모든 input unit과 연결성을 가지고 있다. 그러나, CNN의 경우 filter를 통한 연결성을 가지고 있기에, 각 output unit이 input unit의 일부에만 영향을 받는다. 특정 output unit을 계산하는데 관여하는 input unit들의 영역을 receptive field라고 하는데, 이는 layer를 거칠수록 점점 커지게 된다.
따라서, CNN은 convolution layer를 겹겹이 쌓아 input image의 작은 부분부터 image의 전반적인 부분까지 모두 포착할 수 있다는 특징을 갖는다.
앞 단의 layer는 input image의 작은 부분을, 뒷 단의 layer에서는 image 전반적인 부분을 보게 된다.
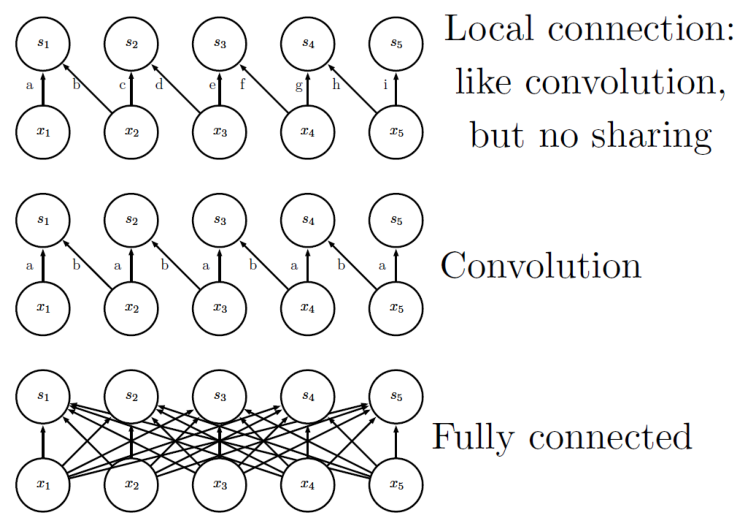
Parameter Sharing
CNN에서는 동일한 filter가 전체 input image에 반복적으로 적용되므로, FNN에 비해 상당히 적은 개수의 parameter를 가진다.
예를 들어, input size가 320x280, kernel size가 2x1라고 하자. 이 경우, output size는 319x280이 된다. 이 때, 필요한 parameter의 개수는 CNN의 경우 2, FNN의 경우 319x280x320x280 (> 8e9)가 된다.
이러한 특징으로 인해, CNN은 보다 빠른 연산이 가능하다. 또한, 모델의 flexibility가 낮아져 overfitting이 방지된다.
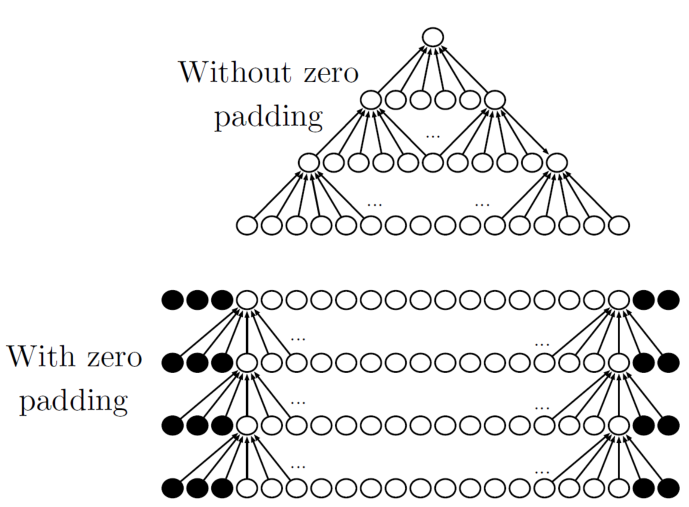
Zero Padding
Zero padding이란 convolution 전에 입력 데이터의 경계에 0을 추가하여 입력 데이터의 크기를 인위적으로 확장하는 방법을 말한다.
Zero padding을 사용하지 않으면, convolution 연산 후에 output의 크기가 계속 감소하게 된다. 또한, zero-padding을 통해 input의 가장자리 부분에 대한 정보가 손실되지 않도록 할 수 있다.
Input과 output의 크기가 같도록 padding을 하는 것을 same padding이라고 한다.
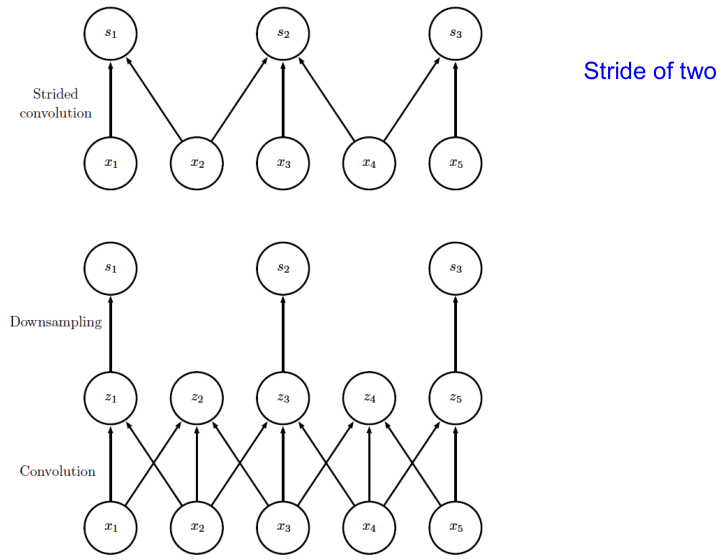
Convolution with Stride
Convolution을 진행할 때, filter가 일정 간격마다 이동하여 계산을 진행한다. 이 때, filter가 이동하는 간격을 stride라고 한다. 기본적으로 stride는 1이지만 (한 칸씩 이동), stride를 2 이상으로 설정할 수도 있다.
Pooling Layer
Pooling이란 특정 위치의 값을 그 주변 값들을 이용한 statistic으로 나타내는 방법을 의미한다. 간단하게 주변 값들 중 가장 큰 값 하나를 취하는 max pooling, 평균을 내는 average pooling 등의 방법이 존재한다.
Pooling을 통해 input의 미세한 변화에 보다 robust하게 학습을 진행할 수 있고, feature를 잘 뽑아내면서 dimension을 줄일 수 있다 (downsampling).
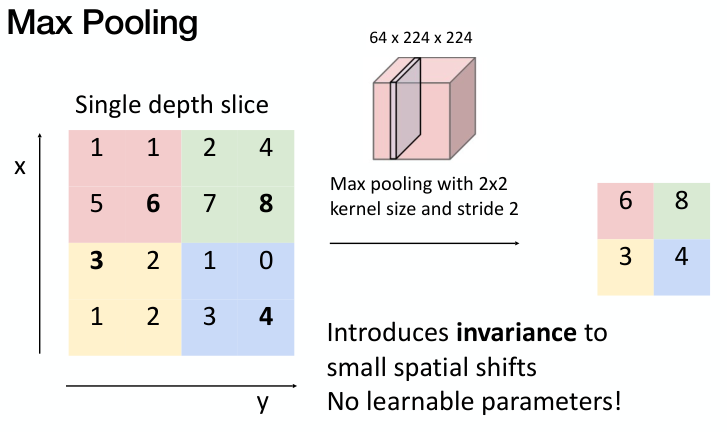
Pooling 과정에서도 stride를 적용할 수 있다. 만약 input image의 dimension이 C x H x W이고, pooling kernel의 크기가 K x K, Stride를 S 만큼 한다고 하자.
이 경우, output image의 dimension은 C x H’ x W’이 되며, 이 때의 H’와 W’는 다음과 같다.
- H’ = (H - K) / S + 1
- W’ = (W - K) / S + 1
일반적으로 pooling은 max pooling, K=2 or 3, S=2 로 사용한다.
Pooling layer에는 학습되는 parameter가 따로 없다.
Major CNN Architectures
LeNet-5
LeNet-5는 MNIST dataset을 활용한 수기 숫자 인식을 위한 모델로 Yann LeCun과 동료들이 1998년에 제안한 초기 CNN 모델이다. LeNet-5는 현대 CNN의 기초가 된다.
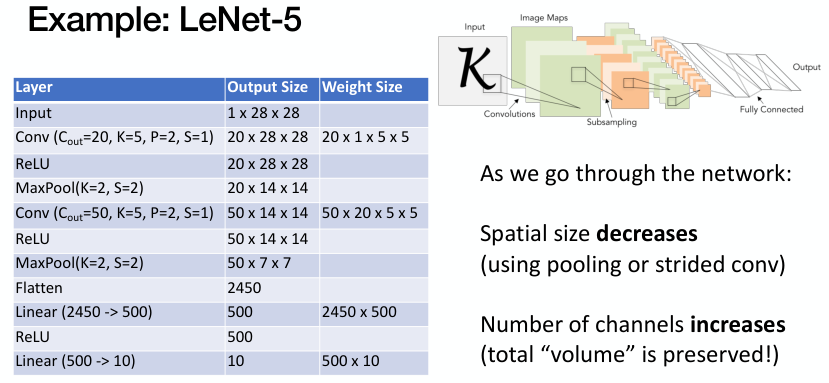
앞서 설명한 convolution layer와 pooling layer를 반복적으로 거쳐 나온 feature vector에 fully connected layer와 softmax를 적용하여, 최종적인 classification을 수행한다.
AlexNet
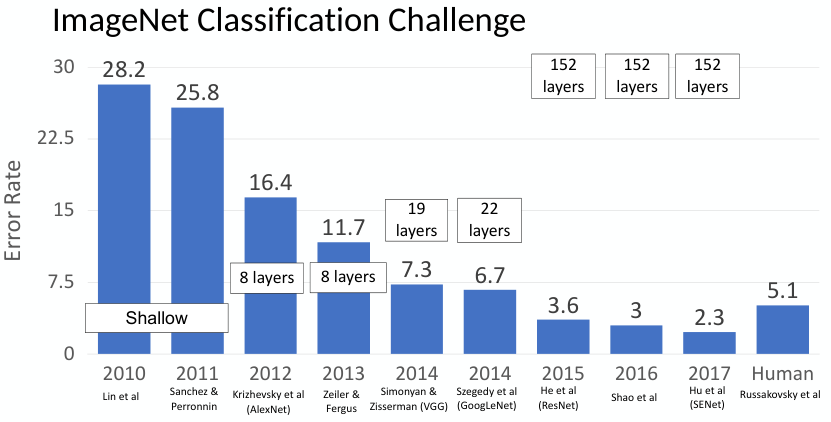
그러나, CNN은 등장 초기부터 주목받은 것은 아니었다. CNN 뿐만 아니라 deep learning은 ImageNet Classification Challenge (정식 명칭: ILSVRC)에서 2012년 AlexNet이 획기적인 성과를 거둔 것을 계기로 크게 성장하였다.
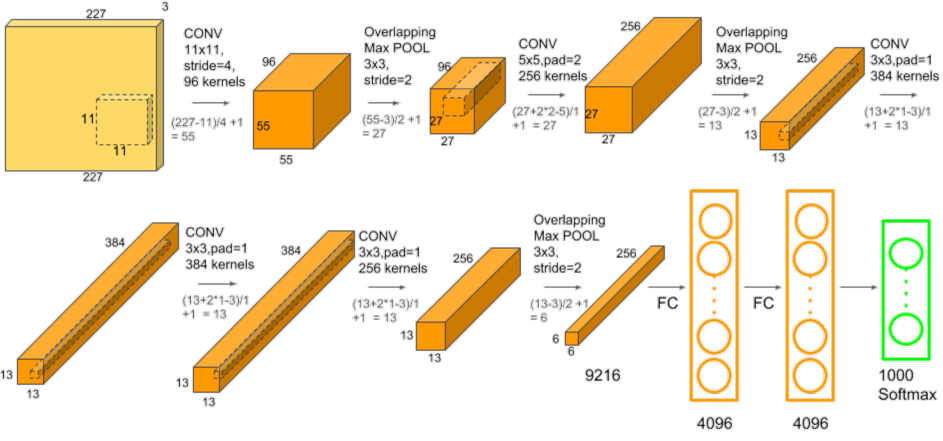
Alexnet의 구조는 다음과 같다. LeNet-5 모델과 비교하면, 기본적인 architecture는 비슷하나, layer와 parameter 수가 더 많아진 것을 알 수 있다. 특이 사항으로는 GPU를 이용한 parallel computing, ReLU의 사용 등이 있다.
모델이 좀 더 복잡해진 대신, 학습에 사용되는 data의 양이 훨씬 많아졌기에 보다 좋은 성능을 낼 수 있었다.
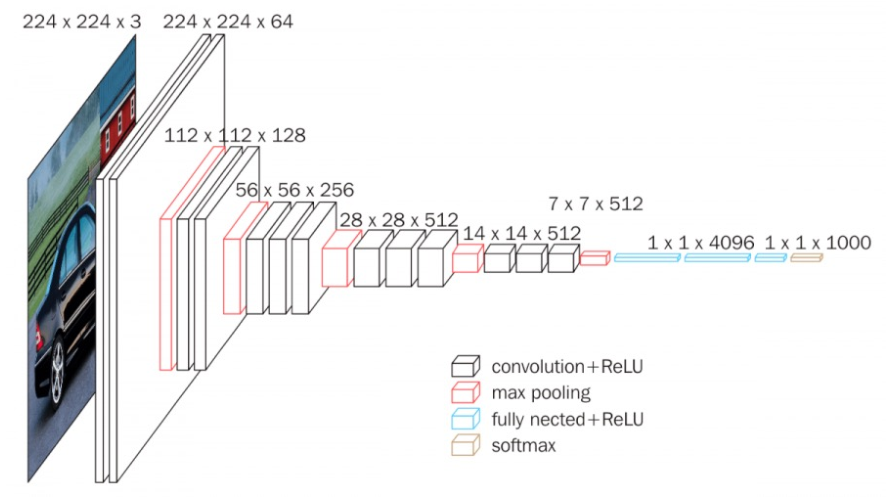
VGG16
AlexNet에서는 다양한 크기의 filter(11, 5 등)을 사용했으나, VGG16에서는 3x3 size의 filter만을 사용하였다. 또한, 8개의 layer를 갖는 AlexNet에 비해 VGG16은 16개의 layer를 갖는다.
GoogLeNet
VGG16은 단순하고 일관된 구조를 가진 layer의 수를 늘려 성능을 향상 시켰는데, 이는 computation cost(memory와 time 모두)가 크다는 단점이 있었다.
GoogLeNet은 inception module을 도입하여 다양한 크기의 filter를 병렬로 사용하여 computation을 감소시키고 성능을 향상시켰다. Inception module이란 서로 다른 size의 filter를 사용하여 여러개의 feature를 뽑아내고, 이를 하나로 합치는 역할을 수행한다.
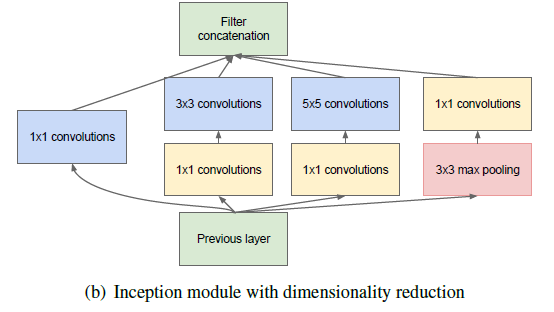
이 외에도 global average pooling과 같은 테크닉을 통해 layer의 수가 22개로 더 늘어났음에도 훨씬 빠르게 학습이 가능하였다.
ResNet
2015년 ILSVRC에서 가장 좋은 성능을 기록한 ResNet은 152개의 layer를 가진 CNN 모델이다. ResNet의 가장 큰 특징은 shortcut connection 또는 skip connection이다. Shortcut connection은 NN에서 일부 layer를 건너뛰어 이전 layer의 output을 이후 layer의 input으로 직접 전달하는 연결방식을 말한다.
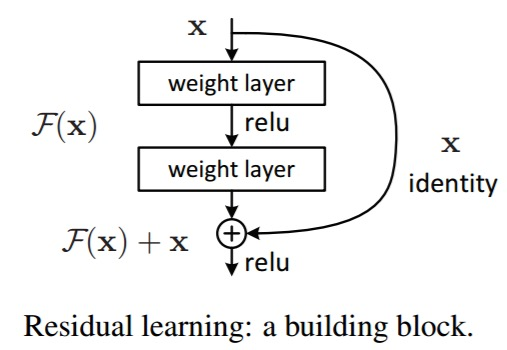
Shortcut connection을 적용하면, 최종 output으로부터 각 layer 까지의 path가 짧아지게 되어 vanishing gradient 문제를 어느정도 완화 할 수 있고, 이를 통해 매우 깊은 모델에서도 학습이 안정적으로 진행된다.
Skip connection 기법은 CNN 외 deep learning 모델에서도 자주 사용된다.