Advanced Regularization
Regularization은 model의 flexibility를 조절하여 overfitting을 방지하고, model의 성능을 향상시키기 위해 사용되는 기법을 말한다.
앞서 ML에 대한 posting 중에서 norm penalty (ridge, lasso)를 활용한 regularization과 early stopping 기법에 대해서 소개한 바가 있다. 여기서는 deep learning 모델 구현에서 사용되는 추가적인 regularization 기법을 소개한다.
Data Augmentation
Deep learning 뿐만 아니라 모든 machine learning에서 test error를 낮추는 가장 좋은 방법은 다양한 데이터를 더 많이 학습하는 것이다.
Data augmentation은 기존 data를 기반으로 새로운 (fake) data를 만들고, 이를 training data에 포함하는 방법이다. Data augmentation은 object recognition 문제에 특히 효과적이라는 것이 알려져 있다.
Training data의 양을 늘리려고 한다면, log-scale (2x, 4x, 8x, …)로 늘리는 것이 적합하다.
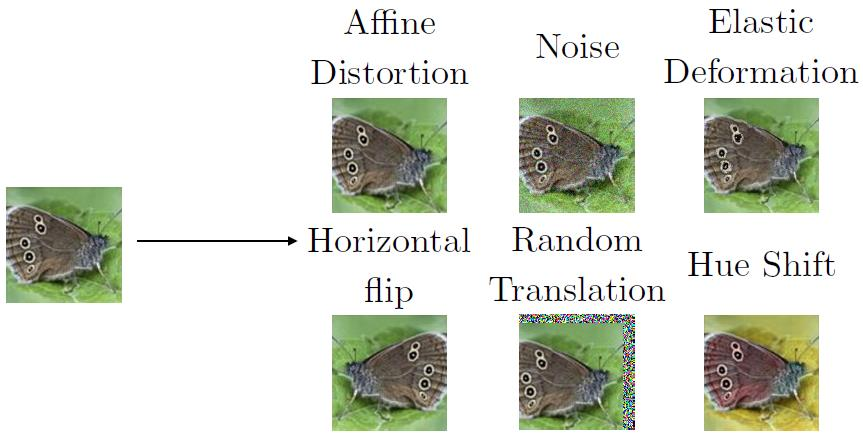
또한, 일반적으로 neural net (NN)은 noise에 대해서 robust하지 않다는 것이 알려져 있는데, robustness를 증가시키기 위해 training data에 약간의 random noise를 첨가하여 학습을 진행하는 방법도 가능하다.
Multi-task Learning
Multi-task learning (MTL)이란 서로 다른 작업을 진행하는 NN에서, 일부 node를 sharing 하도록 제한하는 방식이다.
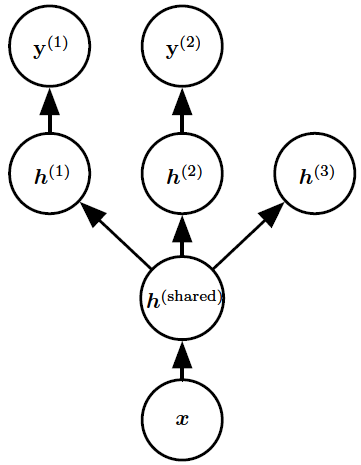
이 방식은 일반적으로 앞단 layer에 적용되며, 각 작업에 대한 학습은 sharing된 neuron 위에 개별 layer를 얹어 이를 학습하는 방식으로 진행된다.
Node를 완전하게 sharing하는 경우 hard parameter sharing이라고 하고, 각 task별 node에 상호간의 constraints가 존재하는 경우 soft parameter sharing이라고 한다.
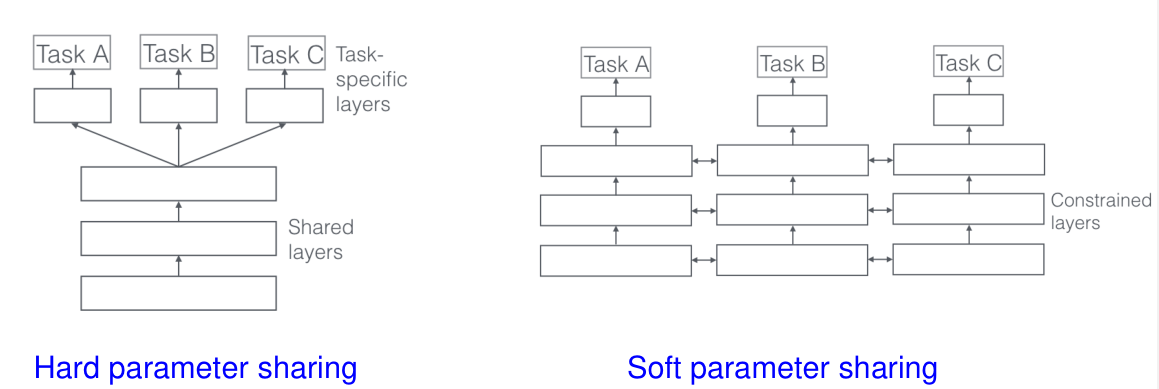
일반적으로 MTL을 적용하면, 서로 다른 작업에서 얻은 데이터가 다른 작업의 학습에도 도움이 되므로 data augmentation 효과를 얻는다. 또한, 다양한 작업에서의 학습 정보가 다른 작업의 성능을 향상시킬 수 있다.
Parameter Tying and Sharing
MTL에서의 핵심 아이디어는 서로 다른 task에 대해서 parameter를 sharing하거나 제약을 두어 모델의 일반성(generalization)을 증가시키는 것이다. 이러한 아이디어는 꼭 MTL 뿐만 아니라 다른 학습 모델에서도 적용이 가능하다.
예를 들어, CNN 모델의 경우 모든 image location에 대해서 동일한 filter를 적용한다. 즉, parameter sharing으로 볼 수 있다.
Parameter sharing 뿐만 아니라, 모델의 특정 parameter의 값에 대한 제약을 주는 parameter tying 방식도 가능하다.
이렇듯 parameter에 제약을 주게되면, 모델의 일반성이 증가하고, parameter의 수가 감소하게 되며, 더 적은 data 수에 대해서도 효과적으로 학습이 가능해진다는 장점이 있다. 물론 제약이 너무 강하게되면 모델 자체의 예측력이 좋아지지 않으므로, 적절한 hyperparameter tuning이 필요하다.
Model Averaging
Model averaging은 bagging과 random forest에서 다뤘던 ensemble 방법과 같이, bootstrap dataset을 활용하여 서로 다른 유사한 모델을 여러개 만들고, 이 모델들의 결과를 합쳐서 최종 결과를 산출하는 방식이다.
NN의 경우, 같은 작업을 수행하는 서로 다른 모델을 천차만별로 만들 수 있다. 즉, 일반적으로 model averaging 방법을 적용하기가 쉽다는 장점이 있다. 일반적으로 다른 NN 모델을 만드는 방법들은 다음과 같다.
- Parameter initialization을 변경
- Minibatch를 random하게 선택
- Hyperparameter 변경
- 모델에 non-deterministic 요소를 구현
Dropout
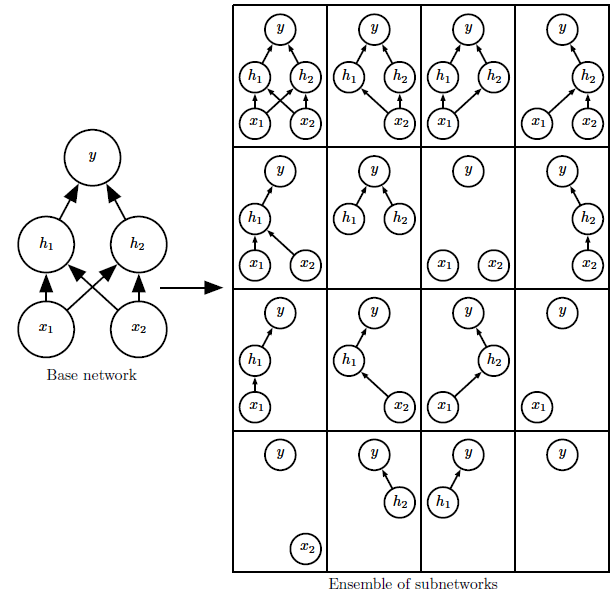
Dropout은 매 forward 작업마다, random하게 선택한 neuron을 0으로 만드는 방법이다. 얼마나 많은 neuron을 0으로 만들지를 hyperparameter로 가지며, 일반적으로는 0.5로 설정한다.
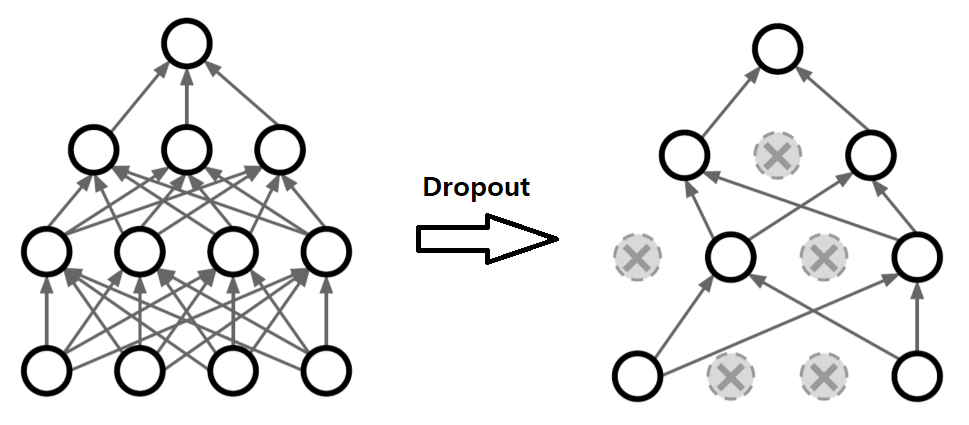
Dropout은 사이즈가 큰 NN 모델에서 practical하게 ensemble을 구현할 수 있게 만드는 방법이 된다. 일반적으로 ensemble을 구현하기 위해서는 각기 다른 모델들을 모두 학습시켜야 하는 어려움이 있지만, dropout을 이용하면 보다 적은 계산 비용으로도 유사한 효과를 낼 수 있다.
Inverted Dropout
50% dropout을 모델에 적용한다고 하자.
이 때, standard dropout은 training 과정에서 따로 scaling 없이 50% dropout을 수행한다. 이 경우, 50%의 input data가 0으로 바뀐 것과 같은 효과가 나기에, 해당 dropout을 거친 후의 matrix multiplication output은 기존 output의 대략 50% 정도의 값을 갖는다. 이 후 test 과정에서는 dropout을 적용하지 않기 때문에, output이 실제 training에서 학습된 값보다 더 크게 나타날 수 있다. 즉, 50% standard dropout이 적용된 training을 거친 모델에 대해서는 test 과정에서 activation function에 적용하기 전 0.5 (=50%)의 값을 곱해주어야만 training의 결과대로 test를 진행한다.
Inverted dropout은 standard dropout에서 output의 크기가 달라지는 현상을 방지하는 dropout 방식으로, training 과정에서 input data에 대해 1/0.5, 즉 2의 값을 모두 곱해준 후 dropout된 layer를 통과시킨다. 즉, 50% dropout으로 인해 상대적으로 작아지는 값의 크기를 input을 미리 키워줌으로써 방지한다. 따라서, inverted dropout이 적용된 모델의 경우 test 과정에 보정을 따로 할 필요가 없다.
Inverted dropout이 일반적으로 더 common한 setting이다.